Introduction
So many times I’ve heart people mentioning aligned memory access. I even protected memory alignment considerations when argued over some software design with my colleagues. I wanted to add few padding bytes into some packed structure to make the structure memory aligned and my colleagues could not understand why I am doing this. This is when I started wondering why I am bothering anyway. I mean, this memory alignment thing, it probably does something useful, but on some esoteric architectures like ALPHA and alike. Do I really need it on x86?
I’ve seen some reports about effects of aligned memory access, yet I couldn’t find some numbers that give a handy indication. I did find lots of university papers with lots of Greek letters and some complex formulas, few books dedicated to the subject and some documents about how bad unaligned memory access is. But really, how bad it is?
So, I decided to check things myself.
What I wanted to see is how much objective time it takes for the CPU to complete an aligned memory access versus a unaligned memory access. By objective time I mean same thing you see on your watch. Yet, since what I am interested in is actually a ratio, we can safely drop the time units. I wanted to test things on x86. No Sparcs and ALPHAs. Sorry mk68000 and PowerPC. Also, I wanted to test a native architecture memory unit: on 32-bit platform that would be reading/writing 32-bit long variable; on 64-bit platform that would be 64-bit long variable. Finally, I wanted to eliminate affects of L2 cache.
This is how I did the test.
The theory
What could be the problem you may ask?
The problem starts in the memory chip. Memory is capable to read certain number of bytes at a time. If you try to read from unaligned memory address, your request will cause RAM chip to do two read operations. For instance, assuming RAM works with units of 8 bytes, trying to read 8 bytes from relative offset of 5 will cause RAM chips to do two read operations. First will read bytes 0-7. Second will read bytes 8-15. As a result, the relatively slow memory access will become even slower.
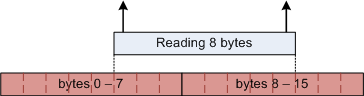
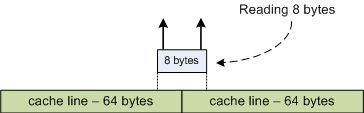
Luckily hardware developers learned to overcome this problem long time ago. Actually the solution is not absolute and the ultimate problem remains. In modern computers CPU caches memory it reads. Memory cache build of 32 and 64 byte long cache lines. Even when you read just one byte from the memory, CPU reads a complete cache line and places it into the cache. This way reading 8 bytes from offset 5 or from offset 0 makes no difference – CPU reads 64 bytes in any case.
However things get not so pretty when you read from a memory address that is not on a cache line boundary. In that case CPU will read two complete cache lines. That is 128 bytes instead of only 8. This is a huge overhead and this is the overhead I would like to demonstrate you.
Now I guess you already noticed that I only talk about reads, but not about write memory accesses. This is because I think that memory reads should give us good enough results. The thing is that when you write some data into the memory, CPU does two things. First it loads cache line into cache. Then it modifies part of the line in the cache. Note that it does not write the cache line back to memory immediately. Instead it waits for more appropriate time (for instance when its less busy or, in SMP systems, when other processor needs this cache line).
We’ve already seen that, at least theoretically speaking, problem that effects performance of unaligned memory access is the time it takes for the CPU to transfer memory to the cache. Compared to this, time it takes for the CPU to modify few bytes in the cache line is negligible. As a result, its enough to test only the reads.
Measurements
Once we’ve figured out what to do, lets talk about how we’re going to do it. First of all, we have to, somehow, measure time. Moreover, we have to measure it precisely.
Next thing I can think of after forcing myself to stop looking at my Swiss watch
was, of course, the rdtsc instruction. After all, what can serve us better
than built into CPU clock ticks counter and an instruction that reads it?
The thing is that modern x86 CPUs has an internal clock tick counter register or as folks at Intel call it, the time-stamp counter. It is incremented with at a constant rate, once every CPU clock tick. So, even fastest CPU instruction should take no less than one unit of measurement to execute. Conveniently, Intel engineers has added an instruction that allows one to read the value of the register.
Implementation
Before diving into actual code that proves our little theory, we should
understand that rdtsc gives us very precise results. So precise that the
rdtsc instruction itself can affect it. Therefore, simply reading time-stamp
register before and after reading 8 bytes from memory is not enough. The rdtsc
instruction itself may take more time than the actual read.
To avoid this sort of interference, we should do many 8 byte reads. This way we
will minimize effect of the rdtsc instruction itself.
Next problem that our test should address has to do with L2 cache. When reading the memory, we have to make sure that it is not yet in the cache. We want the CPU to read the memory into the cache and not to use values that are already in the cache.
Simplest way to overcome this problem is to allocate large buffer of “fresh” memory every time we do the test, work with that memory and release it. Then we have to repeat the test several times, drop several fastest and slowest results and calculate an average. We will receive objective results most of the time, but not always. Repeating test several times, dropping best and worse results and then calculating the average should eliminate “the noise”.
Meet the hardware
There is one hardware limitation when dealing with rdtsc instruction. Older
CPUs (Pentium 3 for instance and even some Pentium 4’s and Xeon’s) has the
internal time-stamp register work in slightly different manner, incrementing
every instruction and not every clock tick. As a result, on older CPUs we would
get a subjective result. Not good. Therefore, we have to use somewhat modern
machine, with modern CPUs. This is what I have at hand.
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 23
model name : Intel(R) Xeon(R) CPU E5450 @ 3.00GHz
stepping : 6
cpu MHz : 2992.526
cache size : 6144 KB
physical id : 0
siblings : 4
core id : 0
cpu cores : 4
fpu : yes
fpu_exception : yes
cpuid level : 10
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat
pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm syscall nx lm constant_tsc pni
monitor ds_cpl vmx est tm2 ssse3 cx16 xtpr dca lahf_lm
bogomips : 5989.11
clflush size : 64
cache_alignment : 64
address sizes : 38 bits physical, 48 bits virtual
power management:
Implementation details
Now to the details. Allocating large memory buffers in kernel can be a bit of a problem. We can however allocate 1MB buffer without worrying too much about allocation errors. 1Mb is smaller than common cache size, but we’ve found a way to avoid cache implications, so no problems here.
Since we’re on 64-bit machine, we want to run through the complete buffer and
read 8 bytes at a time. The machine I am using for the test is quiet new and has
64 byte long cache line. Therefore, to avoid reading from already cached 64
bytes, we have to read once every 128 bytes. I.e. we skip 128 bytes every
iteration. Later I call this number step. Also, since we want to simulate
unaligned memory access, we should start reading from a certain offset. This
number called indent.
The code
The function below does single test. It receives four arguments, first and
second describing the buffer (pointer and buffer size), third telling where to
start reading from (the indent) and fourth that tells how many bytes to jump
every iteration (the step).
First, function does the shifting by adding the indent to the pointer to
buffer. Next it reads time-stamp counter using rdtscll() macro. This is a
kernel macro that reads time-stamp counter into a long long variable – in this
case, the before variable.
Then the function does the actual test. You can see the memory reads in the
loop. It increments value of the temp pointer by step every iteration.
Finally it calls rdtscll() again to check how much time have passed and
returns the delta.
. . .
unsigned long long do_single_test( unsigned long real_page,
int area_size,
int indent,
int step )
{
volatile unsigned char* page;
volatile unsigned long temp;
unsigned long i;
unsigned long long before = 0;
unsigned long long after = 0;
// Doing the indent...
page = (unsigned char *)(real_page + indent);
// Doing the actual test...
rdtscll( before );
for (i = 0; i < (area_size / step) - 1; i++)
{
temp = *((unsigned long *)page);
page += step;
}
rdtscll( after );
return after - before;
}
. . .
You can get the complete source code of the driver, with appropriate Makefile, here.
The results
I did the test twice, first time with indent equals 62 and second time with
indent 64, i.e. started from offset 62 and 64. Both times I used step equals
128, i.e. jumped 128 bytes at a time. In first test, the value of indent
intentionally caused unaligned memory access. Second test was ok in terms of
memory alignment.
I ran each test 100 times, with 10 seconds delay in between. Then I dropped 10 best and 10 worse results and calculated an average. The final result is this.
Average number of clock ticks for first, the unaligned test was 1,115,326. Average number of ticks for second the aligned test was 512,282. This clearly indicates that in worse case scenario, unaligned memory access can be more than twice slower than aligned one.
Conclusions
We’ve seen that in worse case scenario unaligned memory access can be quiet expensive, in terms of CPU ticks. Luckily, hardware engineers continuously make it harder and harder to reach this scenario. Yet, at least at the moment, it is still quiet doable.
Therefore, while guys at Intel breaking their heads over this problem, it is better to keep your structures well aligned in the memory. This is especially important for large data structures, because such data structures cannot utilize memory cache completely. It is also important for data structures that being rarely (relatively) used. Such data structures tend to disappear from the cache, and has to be returned into cache, each time you access them. To be on the safe side, try to keep your data structures memory aligned, always.
Postscript
Just in case you’re wondering how much time it takes to do the same test on
cached memory, here are the results. I repeated the 64/128 (indent/step)
test twice in a row, on the same memory buffer. We’ve seen the results of the
first test. Repeating same test on cached memory buffer takes 39,380 clock
ticks. That is 13 times less than 64/128 test results and 28 times less than
62/128 test results. Quiet overwhelming, isn’it it?
Here is the code I used to produce the later result.